
Rapid, proactive responses to unexpected system behavior and swift, efficient incident remediation are hallmarks of great IT teams. But the most successful NOC and incident management teams share the following:
- A unified view of how systems are performing so they can quickly identify why issues occur
- An understanding of what action to take when something goes wrong
- Multifaceted context — whether alert payload, runbooks, or the teams to include —to make the right decisions
The right context gives teams visibility across systems, helps them collaborate and share knowledge, and makes every team member more efficient.
Conversely, it’s the infrastructure details trapped in silos — and a lack of full, operational context — that creates unnecessary stress for ITOps, observability, and ITSM teams. It’s what they don’t know that keeps them up at night.
1 in 3 ITOps professionals identify business context as the biggest challenge to effective incident response and management.
Data limitations of legacy tools
Unexpected outages can strike at any time, often with debilitating business consequences. Incomplete context limits proactivity and slows remediation, resulting in painful surprises like:
- Extended bridge calls
- Multiple rounds of escalations between the NOC, L1, L2, and L3 resources
- Waiting for information from infrastructure teams to complete root cause analysis.
Missing even one key piece of information can extend MTTR by minutes or even hours.
With outage costs reaching nearly $24,000 per minute for large enterprises, it’s vital to detect and remediate issues before they disrupt services. Yet, most ITOps teams face the realities of legacy tools and siloed processes that fail to provide the context necessary to meet service-availability goals.
27% of IT leaders surveyed by EMA report that 50% or more of MTTR is wasted waiting for information.
Despite extensive investments in observability and monitoring tools, ITOps teams still have a limited, isolated view of most of their IT systems. Observability tools lack the important context that NOC and ITSM teams need to accelerate incident response, including data from system changes, topology, inventory, prior incidents, knowledge base articles, and runbooks.
Full-context operations with AIOps
Empowering ITOps and ITSM through a collaborative approach is the cornerstone of efficient and improved service availability. This means providing all teams involved in alert and incident response the information they need — quickly and upfront — so they can better understand what happened, why it happened, and what to do about it.
Alerts with context become actionable. You can prioritize and remediate incidents with context quickly. Context comes from across your IT stack, including:
- Monitoring events and alerts
- Hybrid IT topology
- CMDB
- Change data
- Historical ITSM data
Correlating this data across sources paints a unified picture of alerts and incidents. This picture allows you to anticipate issues as they develop and proactively detect, identify, and resolve incidents before they become outages.
In short, full-context operations provide the data, insights, and processes to make every stage of incident management faster, more consistent, and sustainable.
“An alert without context is just noise.”
Jon Brown
Senior Analyst, Enterprise Strategy Group
Recent advances in AI allow machines to augment human capabilities, increasing the efficiency and power of ITOps teams. AI-powered ITOps (AIOps) can help eliminate event noise, extracting only the context teams need. AI can also reveal context such as root cause, prioritize incidents automatically, and even suggest the best steps for remediation.
AI not only integrates and analyzes incident data but helps ensure that everyone on the team has the same knowledge and access. It can help less-experienced team members perform at a higher level while providing your most experienced staff with context they would otherwise not have.
The importance of history: Similar Incidents
Understanding the historical context and specifics of prior incidents is difficult, especially for newer ops staff members. Teams often capture and disseminate details in knowledgebase articles or runbooks, but the full information can be difficult to find, access, and use properly.
Advances in AI allow operations teams to identify and learn from past incidents and outages quickly. Details — including who addressed a previous incident, its impact, and how the team ultimately resolved it — can speed the resolution of a current incident, improve service availability at scale, and help prevent issues from recurring.
The BigPanda Similar Incidents feature uses AI to surface historically relevant data from past incidents and offers operators actionable insights to support the investigation of current issues. Similar Incidents centralizes meaningful, related data and improves knowledge sharing across your organization, helping operators to proactively identify issues previously hidden within tooling silos before they escalate. Similar Incidents also enables them to understand and emulate past actions for faster, more standardized mitigation practices.
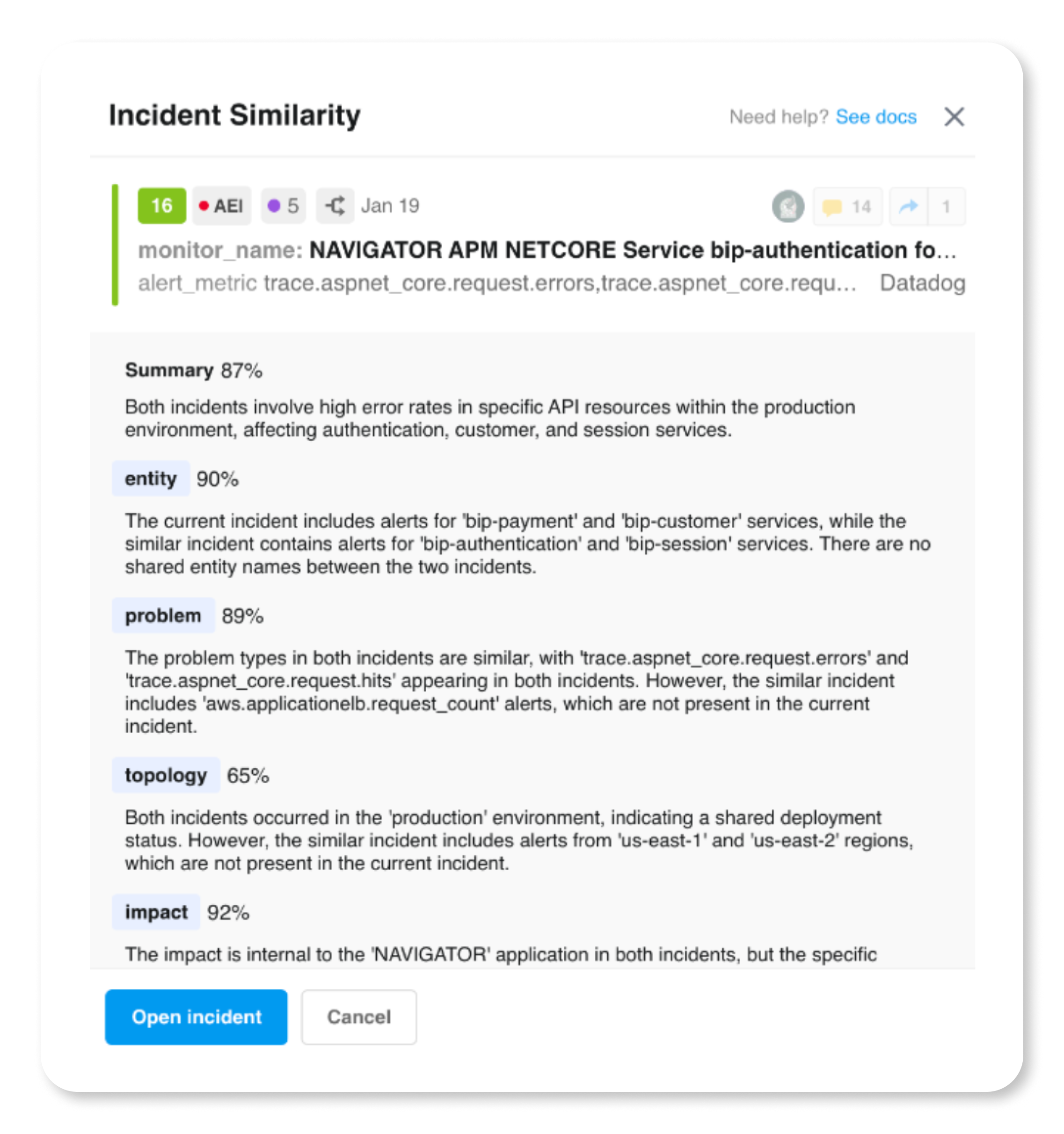
In a practical scenario, an operator facing an incident can review historically similar cases and mimic many of the actions taken to resolve a current issue without having to do a thorough reinvestigation. Similar Incidents does more than merely identify similarities: It can validate prioritization, stakeholder assignments, and remediation actions at any point in the workflow.
Start on the path to full-context operations
Full-context operations is an aspirational goal for ITOps teams, but achieving it remains elusive. Unifying operational data to provide necessary context is challenging. However, with BigPanda, many teams can start immediately using the incident data and context they already have.
“Don’t wait to start your AIOps journey once you are overwhelmed with alerts. Start early to get a single pane of glass.”
Sanjay Chandra
Vice President of IT, Lucid Motors
With BigPanda, operations teams can achieve immediate value in alert noise reduction and enrichment to automate alert resolution. ITSM incident management teams see the value in automated root cause analysis, incident impact, and similarity, which helps them reduce MTTR, become more efficient, and keep essential services running smoothly.
Next Steps
- Learn more about how AI delivers critical context to ITOps in the “Knowledge is power” webinar with ESG’s Jon Brown and BigPanda CIO Jason Walker.
- Download the “ServiceOps 2024” report from EMA Research to explore how ServiceOps can help reduce the frequency, duration, and impact of outages while improving service.




