Our Perspective: Gartner’s 4 Steps to Turbocharge Major Incident-Handling


In his research note “Four Steps to Turbocharge Your Major Incident-Handling Capabilities”, Gartner analyst Kenneth Gonzalez makes a compelling argument for why enterprise IT service operations teams should upgrade their incident management workflow processes.
Here’s BigPanda’s perspective on the topic.
The Real Challenge: Most NOCs Aren’t Automated
Most enterprises are undergoing some form of digital transformation of their business. To keep pace, IT Infrastructure and Operations (I&O) is transforming as well. Investments in the automation of software delivery and infrastructure provisioning over the last few years have made the average I&O organization more agile and responsive. Yet automation of Service Operations – and incident management in particular – has not kept pace.
Often called the Network Operations Center, Digital Operations Center or similar, these I&O teams are the “first responders” to IT incidents. Until recently, no effective automation solutions existed for Level 1 responders to efficiently process the significant volume and variety of monitoring alerts produced by modern infrastructure and application stacks. As a result, they end up missing critical early warning signs that can either avoid major incidents in the first place or enable more rapid response and resolution in the face of them. These stressed out NOCs are now challenged with maintaining their SLAs despite inefficient manual processes that result in significantly higher Mean-Time-To-Detection (MTTD) and Mean-Time-To-Resolution (MTTR)… as well as dealing with unhappy customers.
The challenge is how can NOC managers help their teams cut through the noise to locate and prioritize major incidents more quickly and efficiently. Incident management workflows must be intelligently automated to optimize team productivity and collaboration. Otherwise the results is not only damaging outages and downtime, but also NOC staff churn and burnout.
Step 1: Survey and Assess
BigPanda’s Take:
In addition to Gartner’s recommendations, in our experience enterprises with a more mature approach to IT event management always have a clear focus on key metrics associated with their critical tier-1 applications and services. This comes from an historical understanding of measures such as MTTD, MTTR, number of “Priority 1” versus “Priority 2” level incidents, and so on. Mature I&O organizations then publish this list of applications and associated metrics, making it available for review by anyone from C-level executives on down. They define year-over-year reduction targets for these key metrics and often have organizational performance incentives directly tied to achieving these objectives. Consider adding this documentation to the incident response team repository that Gartner recommends.
Step 2: Plan and Prepare
BigPanda’s Take:
The importance of pre-planning incident management processes cannot be overstressed. NOC automation solutions such as BigPanda employ artificial intelligence methods such as machine learning to enable more intelligent response to any IT event. Automation of IT Service Operations helps to manage the end-to-end lifecycle of major incident management. It starts with efficiently processing the huge data streams produced by monitoring tools using algorithms capable of catching the key early warning signs of service issues affecting tier-1 applications. Automation includes providing dynamic and real-time insight as the event continues to unfold, ensuring all systems involved in the incident management process remain synchronized at all times. This high level of awareness allows Level 1 responders to quickly detect and triage underlying issues, either resolving them or to escalating them to Level 2 responders. For response planning and staff training exercises, Algorithmic Service Operations solutions also maintain historical event data in perpetuity for ready reference. This history, combined with intelligent incident signature matching techniques, allow IT operations to quickly assess the appropriate response plan to emerging issues in real-time, based on past resolution procedures.
Step 3: Detect and Respond
BigPanda’s Take:
The automation drive in IT Service Operations seeks to integrate the entire NOC technology stack – from best-in-class monitoring tools to IT Service Management systems for collaboration, ticketing and on-call notification. Automated incident management workflows must flow up and down the stack to marshal the right resources for major incident remediation. First, algorithmic alert correlation methods can detect and flag major incidents. Intelligent automation solutions then employ historical pattern matching intelligence to help recognize and declare major incidents. IT Service Ops team can then respond in a more effective and timely manner to major incidents affecting Tier-1 applications and services. Since these solutions are real time and always up-to-date, all team personnel including Level 1, Level 2, DevOps/SRE, and developers have necessary context on what they need to know as the issue is escalated across the response and resolution chain.
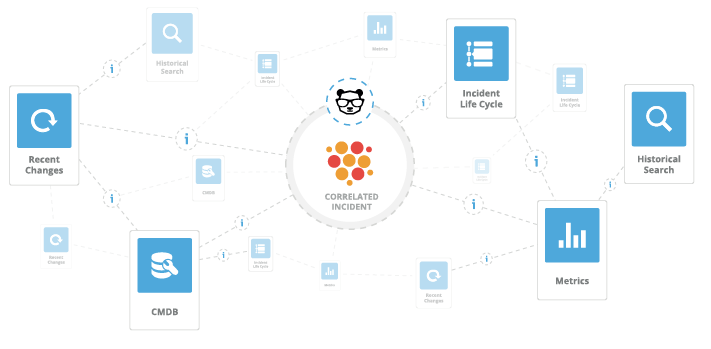 Incidents are enriched with incidents such as metrics, runbooks, recent code deployments, and configuration changes to understand how the issue is impacting the business, why and what to do about it. This tight coordination ultimately results in significantly lower MTTD and MTTR.
Incidents are enriched with incidents such as metrics, runbooks, recent code deployments, and configuration changes to understand how the issue is impacting the business, why and what to do about it. This tight coordination ultimately results in significantly lower MTTD and MTTR.
Step 4: Recover and Reset
BigPanda’s Take:
Algorithmic Service Operations solutions can serve as a single-source-of-truth repository to capture all relevant human and machine data associated with IT events, including major incidents, beyond in-the-moment process automation. This minimizes the burden on personnel to document everything. NOC managers can be confident that the information captured will produce accurate after-incident reports as well as periodic rollup reports on key performance metrics (MTTD, MTTR, etc.) associated with Tier-1 applications and services.
Recommendation: When it comes to managing major IT incidents, get algorithmic.
One effective and scalable solution to automate NOC response protocols is an Algorithmic Service Operations platform. IT Operations leaders can ensure that their team is able to respond efficiently and effectively to major incidents based on business criticality. By leveraging both machine learning algorithms that identify event patterns and seamless integration with ITSM systems, these solutions centralize incident management and provide better operational visibility. The results include less downtime, exceeding SLAs and ultimately, happier IT customers.