
Can observability improve IT Ops?
Date: June 4, 2020
Category: AIOps Tools & Tech
Author: Jason Walker
A Harrowing Landscape
The increasing complexity of modern services is forcing IT Ops teams to employ a growing landscape of disparate tools to monitor the health of their IT Stack. In fact, the number of tools has grown so much in the last few years, that one wonders how IT Ops teams are even able to effectively configure, maintain, ingest, and process all the events that these tools create. The goal of maintaining awareness of service health, and rapidly detecting and remediating incidents and problems that impact that health, is often lost in the noise.

The IT Ops Tools Landscape
In our recent webinar, we discussed how we can leverage the event and change data collected from these monitoring tools, to create better situational awareness and allow IT Ops teams to be proactive in IT incident detection and resolution.
Observability Tools to the Rescue?
“Observability” is a relatively new term which refers to your ability to determine the state of your service based on its external outputs. For example, in a payment service, your degree of observability would be determined by how well you know whether payments are getting processed without errors, and if users are getting what they paid for. That differs from “Monitoring” the app, which in this example would mean the status of its databases, disk usage etc. and whether the service as a whole was up and running. Observability is an attribute of a service, while monitoring is the action taken to detect failures within the components that make up that service. ‘Observability solutions’ are, in general, the monitoring systems that provide some degree of observability.
IT Ops teams need to be able to combine their monitoring outputs at each layer with the change events required to maintain those layers, and achieve high observability of their services, alongside monitoring the health of their components, i.e is the service running properly (are customers getting what they came for), and if not – which of its components is the cause of the service disruption. Observability tools have an important role in this, as they can help detect both component failures and change-related impacts, which are the single largest root cause of service disruptions and outages in today’s fast moving IT.
But today’s Observability tools are siloed, as they are each optimized to monitor the performance of a certain layer within the IT stack, and are unaware of events within the other layers; or, they are optimized to deal with a specific type of output across all components (metrics, logs, anomaly detection), and are blind to other types. This leads to very high observability on a “local” level around each tool, but a very segmented awareness overall. And unfortunately, without a unified strategy in place, IT Ops teams can be overwhelmed as changes or failures trigger both causal and symptomatic alert storms across all these monitoring tools, causing a loss of focus on overall service availability.
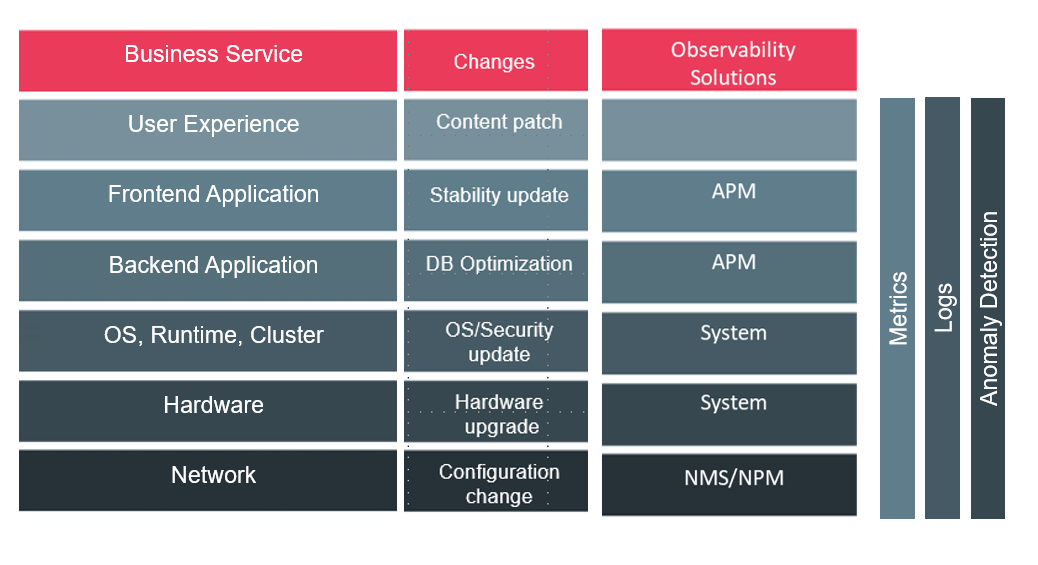
Observability tools can mostly detect and analyze the specific component they were developed for.
Say Hello to Service Level Indicators
A recent strategy developed in IT Ops to help deal with these challenges is the definition, and constant monitoring of, Service Level Indicators (SLI), key metrics that quickly provide an indication from the customer perspective on whether the service is running well. If these SLIs can be correlated with the outputs of layer-specific monitoring and change systems, based on some shared attributes and time-based proximity, the IT Ops team will receive both early detection of service failure, and enough information to determine the causal failure or change.
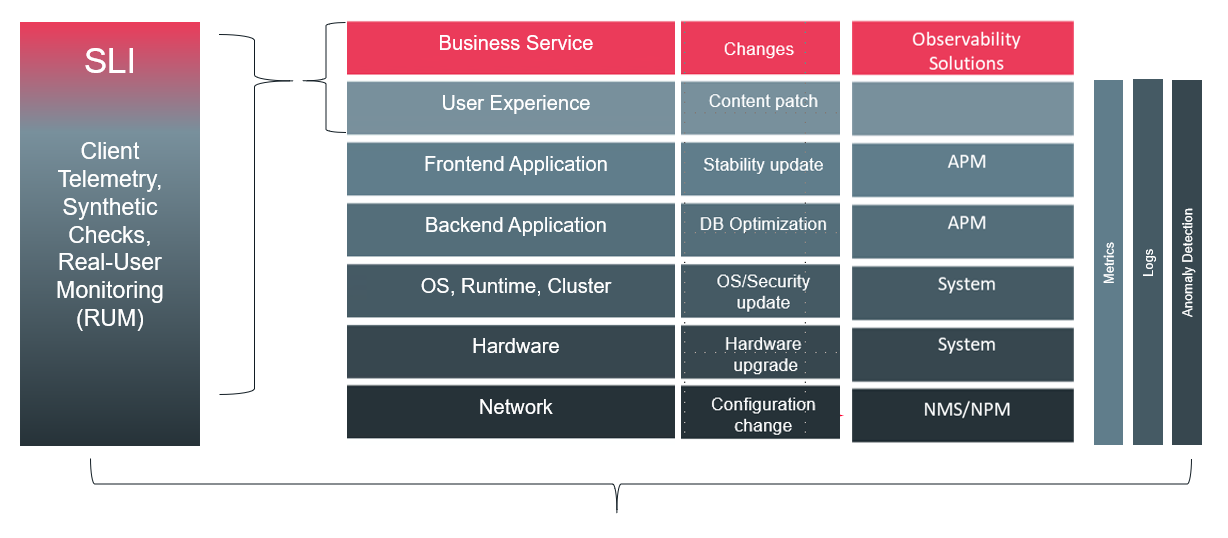
This greatly improves their ability to detect, investigate and resolve incidents in a timely manner and, crucially, maintain service continuity.
Of course, implementing this structure requires several prerequisites and has implications on current processes within the organization. But this is where it gets interesting, and is simpler than it may seem… To learn all the details, understand more about SLIs and learn why implementing true observability lowers the total cost of ownership of your IT Ops tools, we invite you to watch our webinar on-demand.




