Use full context to unite observability and ops teams

IT teams are the invisible engines powering every modern organization. Yet they battle constantly to ensure the availability and reliability of applications and services across fragmented, hybrid-cloud infrastructures. In particular:
- Observability teams grapple with more than 20 monitoring tools, struggling to gain visibility into services and applications across the IT stack.
- Operations and incident response teams face a relentless deluge of noisy, unactionable alerts and contextless tickets that require significant manual effort to understand.
Fragmented tools, siloed workflows, and inconsistent manual processes create an IT nightmare. Despite investing millions in observability and ITSM platforms, teams face alert fatigue, reactive incident response, and persistent outages.
It may seem impossible to guarantee service availability and performance while controlling costs and complexity. Many organizations look to enable cross-functional processes and gain a unified view of their services and applications.
Observability and ITSM platforms are pieces of the puzzle. However, the true strategy is to empower operations and incident responders with comprehensive context on alerts and incidents. With full context, both teams can scale their workflows, leveraging the ability to reduce the volume of tools and data while gaining a holistic, actionable view. They can take action and adapt to challenges with enhanced efficiency and service availability.
“[AIOps] lets us focus on resolving problems instead of combing through thousands of alerts to find the problems…. This is the first time I’ve had any real success in doing that. It’s really transformational and game-changing.”
—Chuck Adkins, Chief Information Officer, New York Stock Exchange
The allure and limits of AI in incident response
Siloed IT departments create significant barriers to effective incident response due to the complexity of tools, data, and changing internal processes. Initially, AI and machine learning appeared to be the ultimate solution. They promised automatic analysis of vast telemetry and observability data to predict and prevent outages. The reality is more complex.
Ideally, using AI to power centralized, end-to-end observability with normalized metrics, events, logs, and traces could make identifying anomalies easier, reduce alert storms, and determine an incident’s root cause automatically. But the sheer volume of data, inconsistency, and high costs associated with observability make it difficult to leverage AI effectively. This is reflected in the current position of AIOps in the “trough of disillusionment” in the 2023 Gartner Hype Cycle for Monitoring and Observability.
Conversely, ITSM teams burdened by legacy configuration management databases (CMDBs) and siloed manual workflows increasingly rely on automating repetitive tasks to enforce consistency and meet modern development demands. Although automation streamlines routine tasks, ITSM teams still need help shortening MTTR and improving operating efficiency.
Why don’t ITSM and observability advances deliver needed efficiency and service availability? In its 2024 study, “Real-world Incident Management,” EMA Research clarifies the source of the problem. When asked, “What percentage of MTTR is inactive time spent waiting for information or response?” 69% of respondents indicated that at least 25% of the time is wasted.
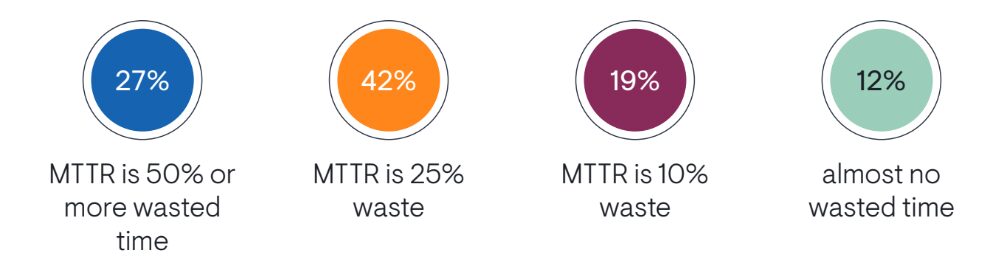
That’s a shocking amount of time lost waiting on data and information from other teams. Or worse, receiving irrelevant details and having to re-escalate tickets through multiple support levels to get the correct data. Teams need a more holistic approach that goes beyond acting on observability or ITSM data independently.
The answer: full-context operations
Empowering ITOps and ITSM through a collaborative approach is the cornerstone of efficient and improved service availability. This means providing all teams involved in incident response the information they need — quickly and upfront — so they can better understand what happened, why it happened, and what to do about it.
Alerts with context become actionable. You can prioritize and remediate incidents with context quickly. Context comes from across your IT stack, including:
- Monitoring events and alerts
- Hybrid IT topology
- CMDB
- Change data
- Historical ITSM data
Correlating this data across sources paints a unified picture of alerts and incidents. This picture allows you to anticipate issues as they develop and proactively detect, identify, and resolve incidents before they become outages.
In short, full-context operations provide the data, insights, and processes to make every stage of incident management faster, more consistent, and sustainable.
“I would love to turn our incident data pipeline into a circle from a line. All three of our teams work in different problem spaces but need and use the same information, over and over again.”
—BigPanda customer
A scenario to consider
An organization experienced an outage of a cloud-based application due to a sudden traffic surge. With full-context ops, the team received enriched alert data with the number of requests received, the resources used, and the error messages generated.
Contextual information, including similar past issues, change data, and other ongoing maintenance activities helped the team identify the cause of the outage. A misconfigured load balancer was distributing traffic unevenly; some servers became overloaded and others were underutilized.
By correlating the enriched alert data with the contextual information, the team quickly identified the root cause and implemented a fix in near real-time.
Unlock the power of full-context operations
With AIOps, both observability and ITSM teams can leverage a unified knowledge base, providing everyone with the same context for faster response and resolution. Standardizing data and workflows across teams enables you to scale with confidence and adapt to complex situations and future challenges.
- Stay ahead of P0 incidents and meet SLAs: Immediately understand incident priority and impact to assign the right teams.
- Investigate and respond consistently: Know the big picture every time so you don’t miss anything and can investigate incidents automatically.
- Eliminate the “mean time to innocence”: Provide historical, real-time, and AI-powered insights to enable more self-service incident management and reduce war rooms, crowded bridge calls, and ticket escalations.
Use full context to make AI actionable and credible
AI, ML, and generative AI hold immense transformative potential for IT. However, their efficacy hinges on one crucial factor: comprehensive, contextual data. Without it, these tools can generate biased, inaccurate results.
Imagine if a recommendation engine suggested irrelevant server upgrades without considering current workloads or resource utilization. Similarly, without context, anomaly detection tools could misinterpret normal fluctuations as critical issues.

Collecting data from multiple sources, correlating events, and enriching them with relevant information provides a comprehensive view of the IT environment. This empowers AI, ML, and generative AI tools to make more accurate predictions and tailored recommendations, ultimately improving decision-making.
Good news: Achieving full context in your IT stack doesn’t require a foundational overhaul of data and processes. BigPanda utilizes AI-powered ITOps to ingest multiple, varied data sources from observability, topology, change, and CMDB tools. It leverages contextual and multidimensional alert correlation to identify actionable alerts. Alert data augmented with generative AI provides a consistent, clear, plain-language summary so operators can understand the incident and identify resolution paths quickly.
This Unified Data Fabric from BigPanda delivers vital information that provides a unique foundation that allows operators to prevent incidents at scale and ensure consistent service availability proactively.
Take a first step toward full context
The good news: The initial steps toward full context are straightforward. Full context can be transformative within your existing IT stack without an infrastructure overhaul. Some steps are as simple as standardizing the hostname in your alert payload. This extra information can make the difference between 99.99999% and 99.99% availability by giving incident responders a head start to address incidents. Improvements like these combined with the full-context BigPanda can deliver, typically reduce an organization’s alert noise by 95% in the first eight weeks of deployment.
Cardinal Health: A study in success
Cardinal Health exemplifies the power of full-context operations. They started their BigPanda and AIOps journey by reducing alert noise and adding an application performance monitoring ID to each alert at the source. Enrichment gives contextual data points on every alert for teams to consume at each stage of incident management. Watch the on-demand Cardinal Health webinar to see the business benefits they achieved and how they enhanced change- and problem-management programs.
Learn how BigPanda can transform your ITOps practice with full-context ops in our e-book, “Full-context Ops: Turn data into patterns, insights, and actions.” Want to talk live? Connect with an expert on full-context operations.