Three LLMs walk into a Network Operations Center…

IT alerts are difficult to understand, even for experienced professionals. The language of IT alerts is akin to an enigmatic code requiring fluency in dozens of observability languages to extract technical meaning and business impact from a stream of seemingly disconnected events, alerts, and notifications.
For example, how many people in your Network Operations Center (NOC) can translate 23 different monitoring alerts and say something like: “Our e-commerce site is running at 50% capacity; however, we are working to fail over to our recovery site in 10 minutes; we’ve also identified the root cause as latency in our cart service due to an unplanned change.”
That human synthesis of all the blinking lights is laborious, time-consuming, and especially hard to scale.
We at BigPanda were curious: How well could large language models (LLMs) from OpenAI, Amazon, and Google translate the IT alert language into plain language? And, under what conditions could these AI tools produce useful analysis, even for veteran NOC incident commanders, by answering basic questions like:
- What is impacted?
- What is the root cause of the issue?
- Can you provide a short summary of the incident for better communication?
The results not only surprised us, they blew us away. The era of LLMs for incident management is upon us.
Experiment 1: Manual correlation of monitoring alerts and LLMs
We started our experiment to reflect what a NOC or ITSM (IT Service Manager) typically has to do when responding to an incident. We sent each LLM model 23 manually correlated alerts related to an incident that span multiple monitoring sources and technology stacks, such as Grafana, Datadog, AppDynamics, and Splunk, across network, database, infrastructure, and application monitoring, for analysis.
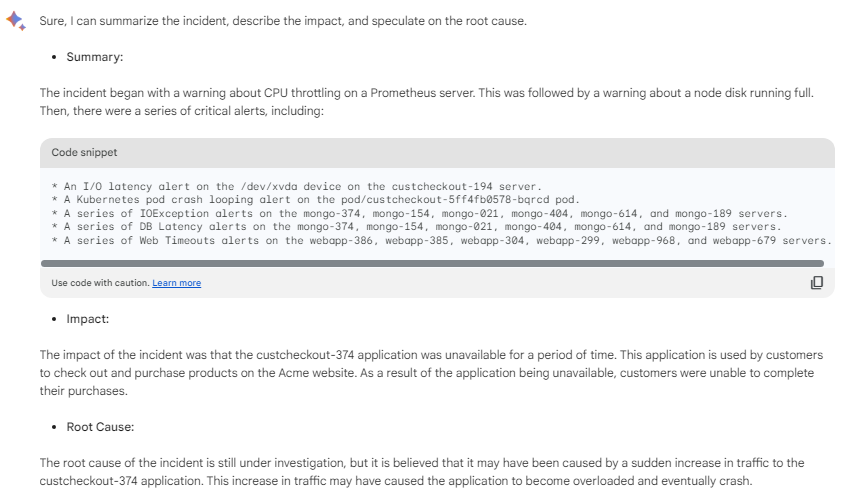
Google Bard analysis

OpenAI ChatGPT analysis
The above screenshots show the LLM assumed the CPU was the cause of the incident, and the impact was localized just to the host itself. But in reality, the root cause was a storage outage experienced across multiple applications that rely on the host nodes.
We were disappointed in the results but not surprised. This frustration is actually experienced by the NOC and first responders on a regular basis. The lack of operational awareness and incident context is like a game of whack-a-mole to identify where a problem started first and where to fix it. It’s not only hard for humans but also for AI.
This illustrates the importance of accuracy in a time of crisis. In this case, the wrong team would have been notified while ignoring the responsible storage and application teams. The true root cause of the issue (storage failure) would have taken exponentially longer to identify correctly.
Experiment 2: Correlated and enriched IT alerts + LLMs
Our second test started by ingesting the same twenty-three alerts across multiple monitoring sources and technology stacks. What we did differently was:
- Correlating related alerts across domains to display impacted applications and users related to an incident and its resolution.
- Ingesting change data to help pinpoint the responsible cause for an incident/outage.
- Enriching alerts with CMDB (configuration management databases), topology, service maps, and trace information to provide an understanding of how affected systems are related and their purpose.
The screenshots below (figure 2) represent output after feeding it payload data from Google Bard.

Figure 2: Output from Google Bard
The initial results of the LLM-driven automated incident analysis not only surprised us, they astounded us.
Each LLM model delivered an accurate, natural language Summary, Impact and Recommendation of the incident. Remarkably, each LLM also identified the correct “needle in the haystack” buried within the 23 enriched alerts.
It correctly found that the 5th alert, the storage failure alert, was the root cause of the outage. Impressively, it didn’t use simple logic like “What failed first?” Instead, it used its extensive expertise in IT systems and operations to understand application topology and form a highly accurate analysis that showed the storage failure triggered the problem.
We next investigated how large language models can be used in production at a typical NOC.
The screenshot below (Fig. 4) is from the BigPanda Incident 360 UI. It shows the 23 correlated alerts and the descriptive metadata that enriched the incident, which includes application impact, dependencies, and CI-level details. The “Summary” tag in BigPanda is used by the NOC team to manually compose an abstract of the incident. ‘Title’ tag is used in BigPanda to communicate incident impact to response teams and is automatically populated in ITSM tools.
The process of composing a “Summary” and “Title” takes at least a few minutes to complete because a first responder has to consider the type of issue, the impact on the technology stack, and what level of detail to communicate in their ITSM tools. The ability to do this quickly, and accurately, is highly dependent on their tenure and expertise.
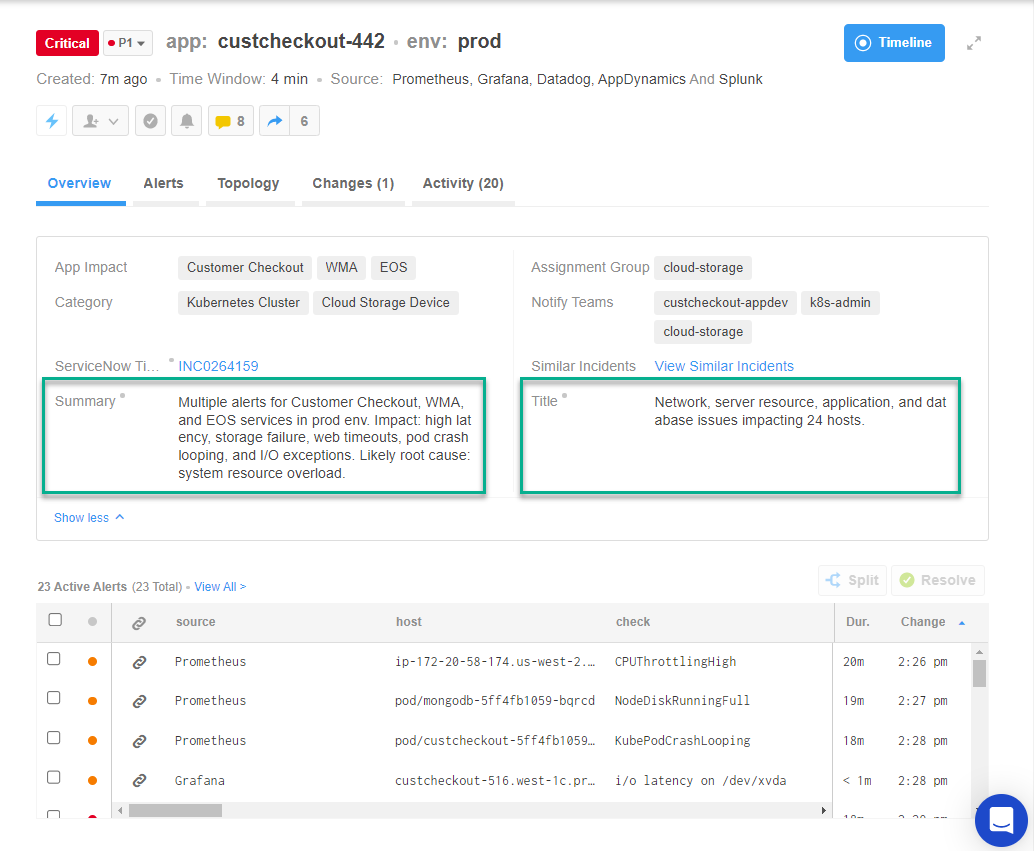
Figure 4: BigPanda Incident 360 UI
Each LLM model delivered an accurate, natural language ‘Summary’ of the incident and a highly relevant ‘Title’. The number of impacted CIs and alerts involved was composed in a clear and concise title that is automatically synced with ServiceNow and the ITSM team (figure 5).
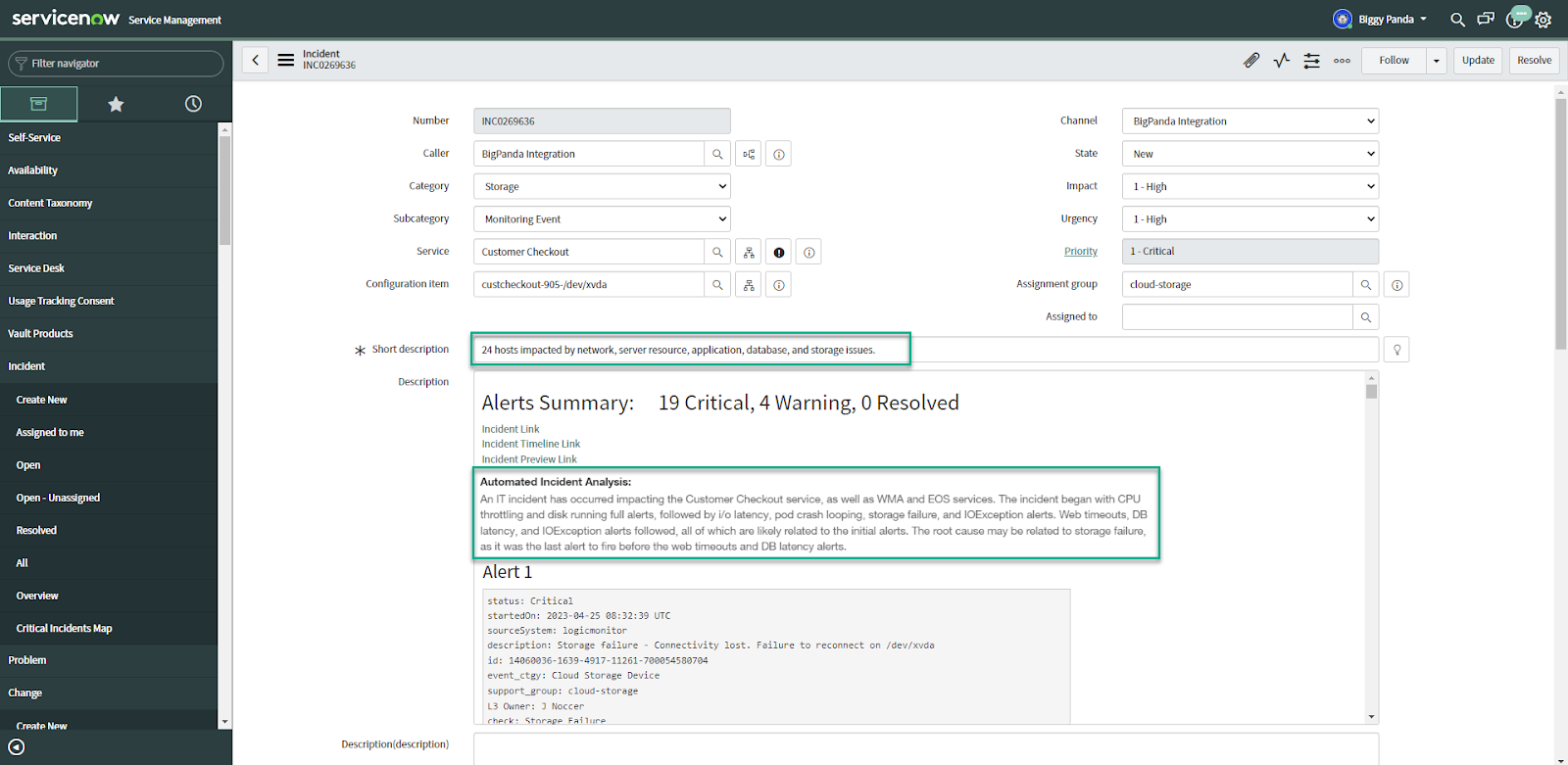
Figure 5: ServiceNow
The probable root cause was also automatically added to the incident details so that anyone investigating the incident would have the information front and center (figure 6).

Figure 6: BigPanda comment
A major step in the forward evolution of Incident Intelligence and AIOps
The power of advanced natural language processing, large language models, and BigPanda’s AIOps open data strategy paves the way for IT operations to scale and automate new activities that previously were too complex to undertake. From our research, we surmise that customers will benefit from:
- Faster incident triage – up to 5 minutes faster per incident, at scale
- Accurate root cause analysis
- Higher incident resolution, with fewer missed incidents and fewer escalated incidents
It’s groundbreaking just to think that you can have every incident translated and explained in natural language, regardless of how urgent the incident is. It’s like having a highly-valued ‘incident commander’ available for any incident, at any time, any day, even on major holidays at 2 in the morning.
Risks using large language models in IT Operations
We know that each LLM has extensive IT domain knowledge that provides valuable insights into infrastructure, applications, and system architecture. However, the “match made in heaven” that is built upon the NOC’s trust utilizing LLMs requires a) descriptive metadata and enrichment to deliver the content of an incident and b) reliable and accurate AI outputs that is pragmatic and explainable to understand its efficacy and value.
Moving forward with large language models and BigPanda
The introduction of large language models has captured the imagination of the world, and we are just beginning to surface the impact LLMs will have on IT operations.
We are currently testing large language models with select BigPanda customers to understand key technology and business requirements to support the automated incident analysis described above.
We invite our existing clients, potential customers, and industry peers to join us on this exciting journey of delivering automated incident analysis to your environments. Please contact me or your account executive to learn more.