
Event chaos or enrichment? Centralized Ops via alert enrichment can untangle the mess
Date: July 9, 2020
Category: AIOps Tools & Tech
Author: Jason Walker
In our recent “IT Ops Demystified – Event Chaos or Enrichment?” webinar our field CTOs discuss how enrichment can help reduce operational costs by an order of magnitude. Here is a quick overview of all the goodness from the chat.
Once upon a time, maybe 15 years ago, IT alerts were a trusted call to action. An alert would fire and tell you what infrastructure element it came from and what its problem was. You would know from the alert’s name and your tribal knowledge what service was affected and how it related to the business. And so you would take that single alert, initiate a single incident, validate and prioritize it, and assign it to someone else in the organization for resolution. And all of that – from a single basic alert such as a high CPU load. What easy times those were… unfortunately those days are long gone.
Overwhelmed IT Ops
These are the days of complex, fast-moving IT. Infrastructure is commoditized, with infrastructure-as-code, lambdas and serverless functions being used to manage services and applications. Software has evolved as well with DevOps, micro services, CI/CD pipelines and more.
Unfortunately IT Ops has been left behind.
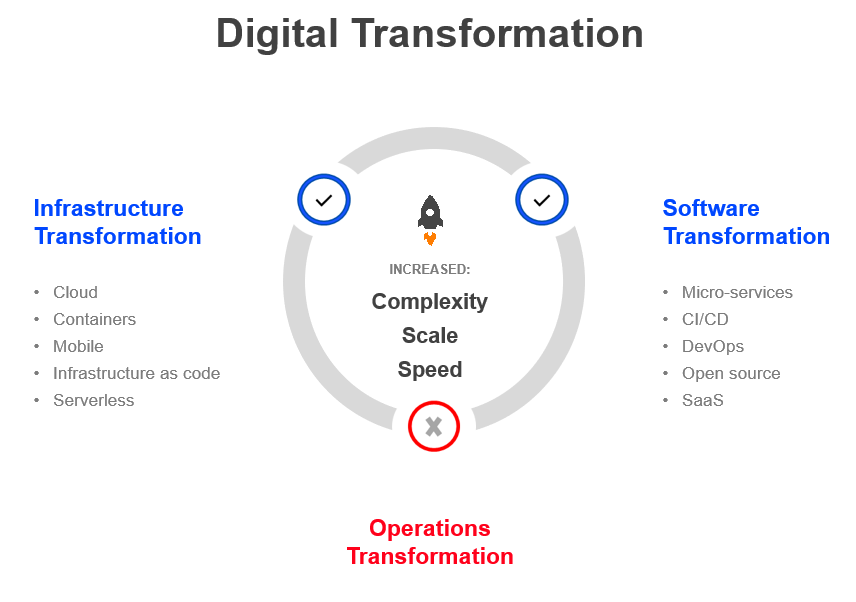
While the digital transformation of both infrastructure and software provided them with resilience and scalability, it also introduced significant complexity, as inter-dependencies multiplied and became more fluid, change frequency increased, and the surface area for security grew. As the volume of alerts from a flourishing-yet-disparate variety of monitoring systems kept growing, so did the efforts of IT Ops to keep up with them. With only traditional tools at their disposal, IT Ops teams found it increasingly difficult to handle the onslaught of non-actionable and out-of context alert noise, until they could no longer maintain situational awareness. Service health was abstracted away from the underlying monitoring, IT Ops was overwhelmed.
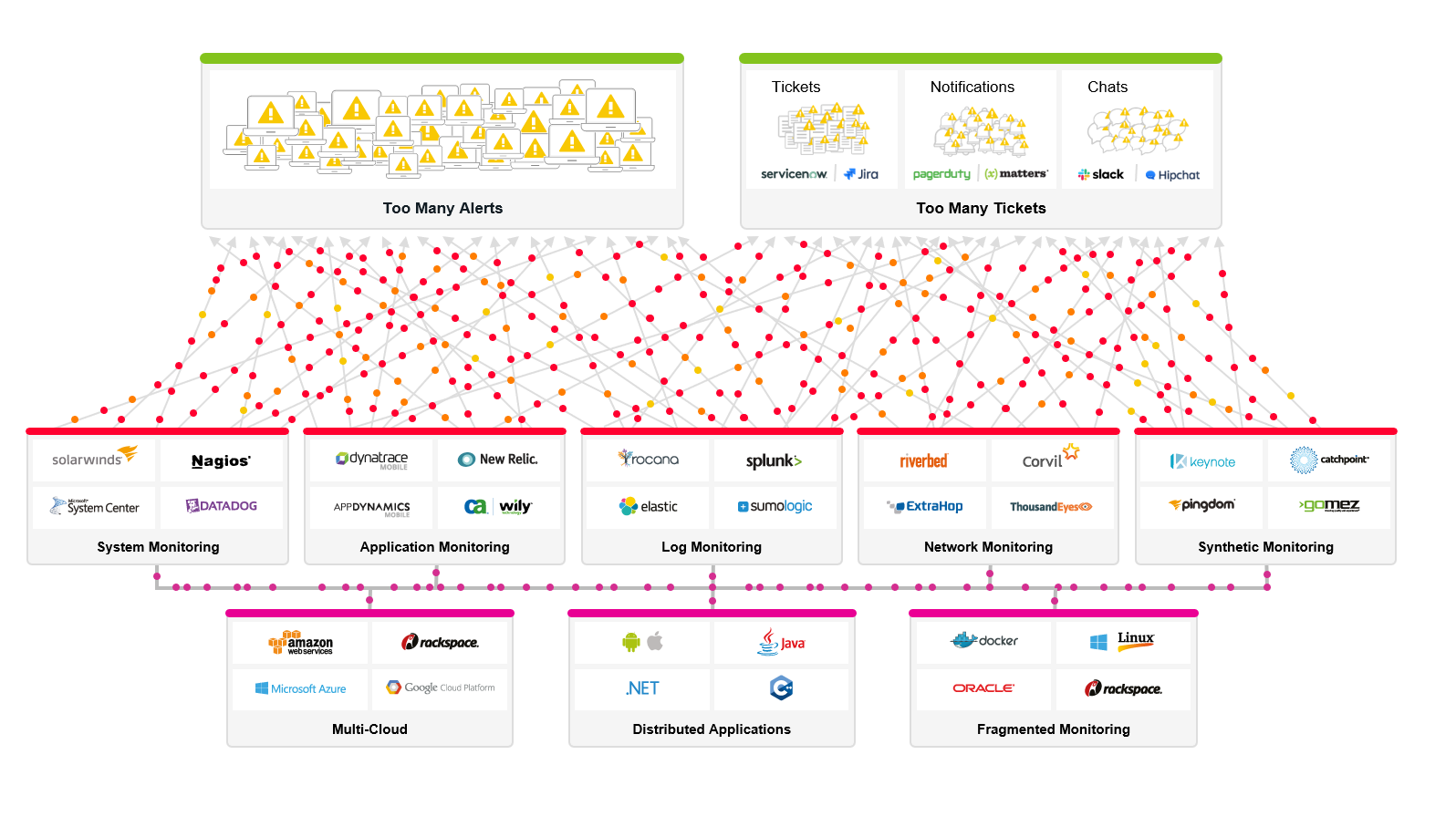
Inadequate Response
When faced with too many alerts and too many tickets – IT Ops teams often found themselves defaulting to one of three unsatisfactory coping mechanisms:
- Actionability. As the events IT Ops was processing no longer gave teams the actionability they were looking for – they would turn to their customer service, user reports, social media, their website and/or external monitoring websites such as downdetecive.com. Here teams could actually learn what was going on. But this saw their customer service costs increase, as they were dealing with service disruptions after the fact.This also increased MTTX, because the teams had to wait for customers to realize something was wrong.
- Bureaucratization. Choosing speed as a main driver, teams became good at processing alerts very quickly, often introducing some automation and integration tools. But this just passed the noise to tier two and tier three engineers, without adding any insight, burdening costlier engineers with the task of filtering noise, while also taking time away from their projects and innovation. This reduced overall efficiency, often expanding live operations to 60%-70% of the IT organization’s time.
- Decentralization. Essentially, IT Ops teams just “gave up” and entrusted SREs and/or DevOps teams with monitoring and operating their own services. But since most of these teams were not aware of the service stack top-to-bottom, they were reacting in many cases to symptomatic alerts as other teams were making changes to infrastructure and/or dependent apps. With no central awareness – detection, analysis and remediation of incidents became expensive and time consuming. Many teams are still operating in this model.
Centralization and Enrichments to the Rescue
Having understood the inadequacies of each of these responses, teams are now realizing that a centralized operation created through alert enrichment can untangle the mess. This is the essence of IT Ops transformation.
As discussed, the goal of monitoring a service stack comes down to actionability – deciding when and how to act. This can be represented in a paradigm that originates in military aviation: Observe, Orient, Decide and Act.
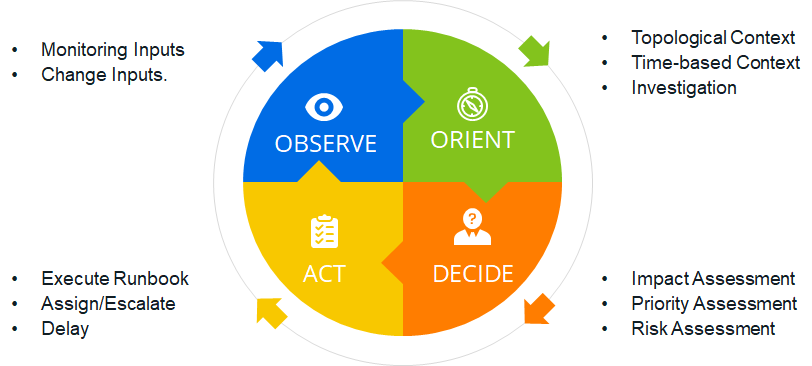
- IT Ops teams need to Observe their systems with monitoring and change tools;
- then Orient based on context: topological, time-based and investigation;
- Decide based on impact, priority and risk assessment;
- and Act by assignment, escalation, runbook automation or delay.
The key for this process is enrichment – adding all the information from all systems to the raw alerts, so that teams are well informed when looking at them, and can perform each of these steps from one central tool. This enrichment can be divided into two major groups.
- Topological enrichment – “decorating” alerts with different attributes from all the systems being monitored in the organization. For example taking an alert from Appdynamics or Splunk, and adding topological data from Kubernetes or VCenter. This enriches a simple CPU load alert that only has a host name, with the relevant service, and application it is affecting. This gives teams the context to understand where this alert is coming from and what service is being affected.
Enriching all the alerts in this fashion also allows IT Ops teams to correlate them into a lower number of incidents: groups of alerts that stem from a common problem. For example, a network device may have failed and all elements downstream from it – infrastructure, applications and databases – are alerting on the basis of lost network connectivity. By correlating all relevant alerts into this one incident, IT Ops teams can shorten the time to detect, analyze and resolve the issue, as they have less noise to deal with and can identify the suspected root cause based on time or topology. - Operational enrichment – information that helps IT Ops teams both orient and handle (prioritize, assign, remediate) the incidents they have just detected.These may include enrichment from change systems, allowing teams to determine what needs to be rolled back to remediate the incident; or enrichment with run books an/or team ownership, that allows automatic execution, escalation and notification; or enrichment with tribal knowledge that allows teams to automate parts of the remediation process and auto communicate with users.
The Bottom Line
Enrichment leads to shorter detection, investigation and remediation times, by creating visibility for root cause analysis and allowing automation for remediation. It also allows for high consistency rates in dealing with incidents, as the manual human factor is highly reduced.
What does this all boil down to? Apart from improved levels of services – all this leads to substantial operational cost reduction. Here is a comparison of incident duration and output consistency for each phase of a typical incident, using (Red) manual event management vs. (Green) automatic enrichment in event management:
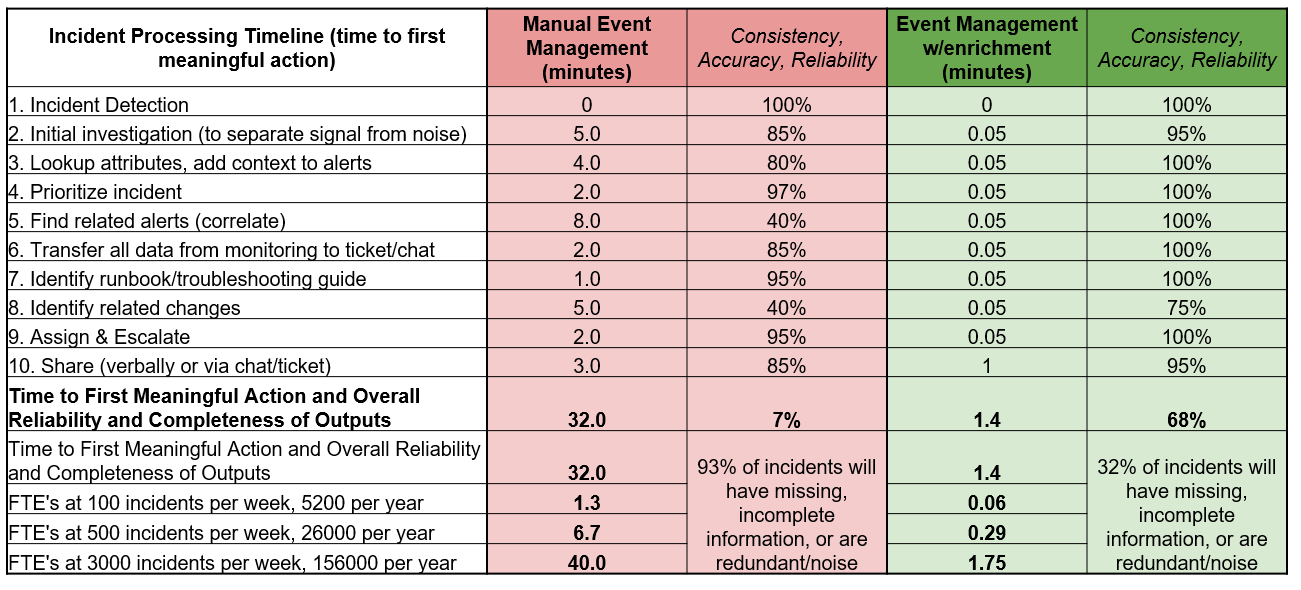
Bottom line: enrichment can improve the time to first meaningful action by a multiple of 22, and in so substantially help save on IT Ops headcount, often up to dozens of FTEs!
While that may sound too good to be true, it actually is based on our experiences with our customers. If you want to get all the details and also understand how BigPanda can help you implement all this, we invite you to watch this webinar on-demand.




